For the past several months, members of our group have been developing a suite of tools built on top of the core STINGER graph data structure to simplify the process of getting streaming data into STINGER, maintaining the online analytics, and getting useful data out from the algorithms. Today we are publicly announcing our efforts and making the source code available on GitHub.
Previous code releases of STINGER demonstrated the key capabilities of the data structure, but many of our users found it difficult to ingest their data. Our new STINGER is a fully multithreaded, multi-process client/server application (see architecture diagram below). The graph database runs as a separate server process. Data is ingested in real-time by "streams" that send batches of edges to the STINGER server via TCP. Each edge stream is handled by an independent thread, and threads are stateless. If your data is formatted as CSV or JSON, we provide for you an ingest stream that can read text from stdin and generate edges using a formatting template.
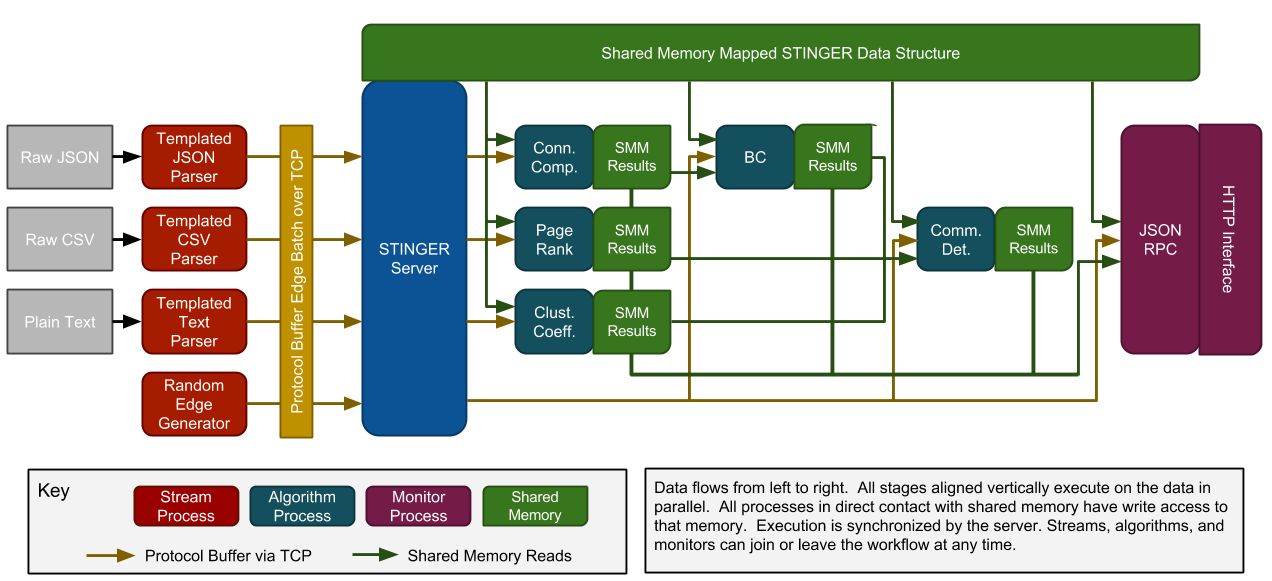
Each analysis algorithm runs as an indepedent process that maps the graph into read-only shared memory. The STINGER server and algorithms take turns executing. When the server receives a batch of edges to be inserted into or deleted from the graph, it first notifies all algorithms with a copy of the batch in what we call the "pre-process" phase. Once all algorithms have signaled ready, the server processes the edge updates and then notifies the algorithms to execute the "post-process" phase. Algorithms map a new copy of the graph into read-only shared memory and finish their computation. This process continues ad infinitum.
We are currently shipping the following streaming algorithms: PageRank, connected components, largest k-core detection, and betweenness centrality.
Algorithms can join and leave at any time. Algorithms can allocate server memory and publish their results so that other algorithms can read them. A special type of algorithm is called a "monitor." A monitor only reads the graph and batches of updates and does not publish. Our first monitor is a web-based interface and visualization tool based on JSONRPC. We have created a JSONRPC server to interface with the STINGER server through an embedded web server. The JSONRPC server enables both stateful and stateless queries to be run on the graph structure and results of algorithms.
Our visualization sandbox uses JavaScript and D3 in the browser to capture algorithm results over time in a user-specified manner. We support Top XX lists and charts, label co-incidence, neighborhood layouts, and labeled graphs.
The next generation of STINGER ecosystem strongly leverages existing open source projects including Mongoose, RapidJSON, d3.js, Google Protocol Buffers, and Twitter Bootstrap. STINGER continues to be licensed as free and open source software under the BSD license.
We are continuing to build out the ecosystem, and we admit that documentation has taken a back seat during this intense period of development. Please send us your thoughts and suggestions. We would like to supplement the system with online snapshot/restore capability for fault tolerance, seamless integration with MySQL data sources, a templated XML parser, query languages, and additional tools for machine learning and streaming data analysis.