 Graph analytics to the rescue!
Graph analytics to the rescue!
Dynamic graphs are all around us. Social networks containing interpersonal relationships and communication patterns. Information on the Internet, Wikipedia, and other datasources. Disease spread networks and bioinformatics problems. Business intelligence and consumer behavior. The right software can help to understand the structure and membership of these networks and many others as they change at speeds of thousands to millions of updates per second.
What does it do?
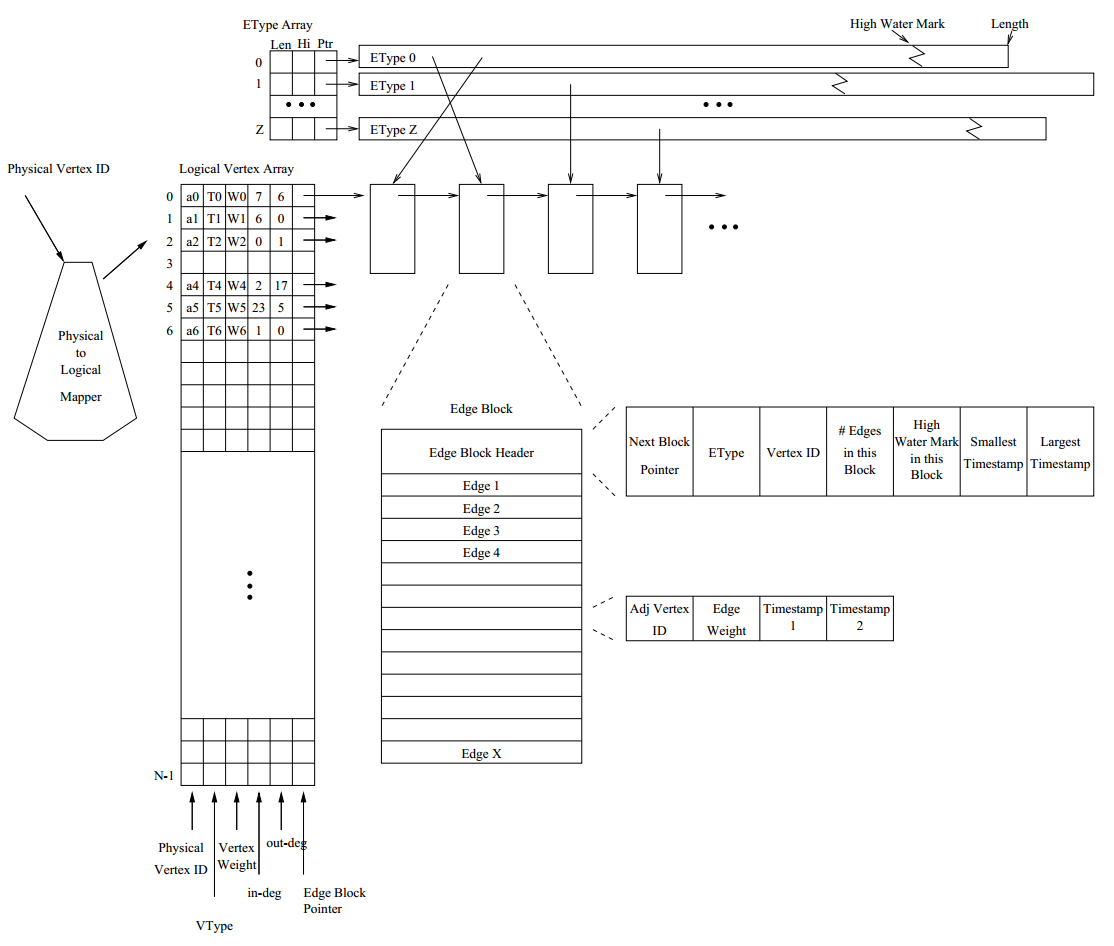
STINGER is many things. At its core, STINGER is a dynamic graph data structure developed at the Georgia Institute of Technology along with colleagues in academia, government, and industry. It is capable of encoding dynamic temporal and semantic relationships between entities as vertices and edges. You can use STINGER to represent, analyze, and understand data from a variety of sources. Nearly anything that can be represented as an abstract set of relationships between entities. For example, in analyzing Twitter, the vertices (entities) might be users, hashtags, or even individual tweet events. Edges (relationships) might represent authorship, retweeting, mentions, following relationships and more. Additionally, STINGER is a library and software package. We have implemented a variety of algorithms on STINGER as part of our research, and they are all available for you to gain insight into your datasets.
How can I use it?
We believe that there are many categories of STINGER users and work to support all of them. Some users may choose to use STINGER as self-contained software package. For these users, our goal is to enable you to download and build STINGER, configure which algorithms you would like to run and the settings for each algorithm, configure STINGER to understand your data, and begin processing your data with no coding knowledge required. For more advanced users that want to incorporate STINGER into their software project, we envision providing productivity-oriented interfaces to STINGER in Python and Java that allow loading data into the graph, querying the graph, managing the execution of analytics in a programatic way. Also, we provide a complete interface to STINGER in C with support for OpenMP including parallel filtering and traversal mechanisms. Lastly, our source is open for you to hack apart and use as you see fit - for more see the following section.
How can I help?
As a Free and Open Source Software project, STINGER receives design input and code development from the original developers, users, and the broader graph analytics community. It has been used and extended under a number of government and industry funded projects. STINGER is available under the BSD license for you to use and hack on as you see fit. We are happy to accept any feedback, requests, and code that you wish to contribute. Our current experimental code base is hosted publicly on GitHub. Read-only access to our Subversion repository containing older versions is publicly available. Anyone can submit patches, pull requests, or issues.